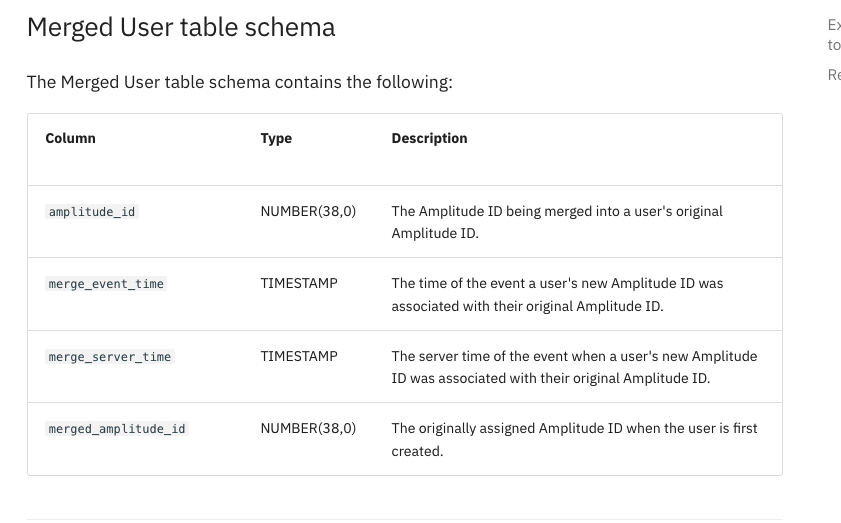
How can I modify my Redshift query to find a unique user that includes the merged Amplitude ID in addition to the WHERE condition?
The results of the query from the Amplitude segmentation and the unique user I found in Redshift are different, even though the WHERE condition and duration are the same. The number of the unique users from Redshift more then amplitude’s result.
I suspect that the difference may be due to the merged Amplitude ID, device ID and user ID.
Could you please help me with this issue?
I’ve already read below articles.
https://help.amplitude.com/hc/en-us/articles/115003135607
https://help.amplitude.com/hc/en-us/articles/206964247-Redshift-Active-users