I'm wanting to pass the result of one formula in as the data input for applying in another formula.
In this case, I want to find out the number of possible unique values for an event's property, and then chart a histogram of how many users fall into the category of having n unique values for the property.
Ex: Let's say the property is US State. Every event has the property US State to track where the user was located in when they generated that event. I'm trying to count my "travelers" - users who have visited more than one state. It doesn't matter which specific states at all, only that they have >1 unique value for US State.
I'd love to be able to do something like this:
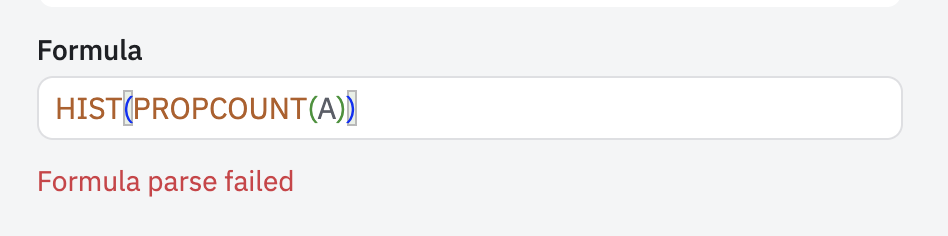
I would like this to result in a chart that has 1-50 on the y axis, and a user count on the x axis. The count of users in the bucket called n=10 would then give me the number of users that have generated events in exactly 10 different US States - any combination of states, in any order of generation, but 10 unique ones.
Perhaps then I may create a cohort off this bucket, and look at which state combinations/sequences/patterns are the most frequent for this group. Or something.
Is this supported? Is there another way to get at this data without developing really complicated nested logical cases in the cohort criteria?

